Retrieval-augmented Memory for Embodied Robots (ReMEmbR)
Preface
The goal of the final project was to replicate a research paper that allowed robots to establish memory and reason through the memory. It could go back to a given position it has already been to with a prompt. For example, if asked where the nearest restroom was, it would be able to path plan to the area where it has seen a restroom.
This video is taken from the original research paper.
Challenges
The paper used the Segway Nova Carter which is built on top of the Jetson AGX Orin. This is an immense difference with our Jetson Nano, almost like comparing a jet to a bicycle. As such, our goal was to replicate this on a constrained and limited hardware platform.
Below is a note of the difference in capability.
- CPU
- GPU
- RAM
- Storage
- I/O
| Aspect | Jetson AGX Orin | Jetson Nano |
|---|---|---|
| Processor | 12-core ARM Cortex-A78AE | Quad-core ARM Cortex-A57 |
| Clock Speed | ~2.2 GHz | ~1.43 GHz |
| Aspect | Jetson AGX Orin | Jetson Nano |
|---|---|---|
| Architecture | NVIDIA Ampere | NVIDIA Maxwell |
| CUDA Cores | 2048 CUDA cores | 128 CUDA cores |
| Tensor Cores | 64 Tensor Cores | None |
| Performance (Trillions of Operations Per Second) | 275 TOPS | ~0.5 TOPS |
| Aspect | Jetson AGX Orin | Jetson Nano |
|---|---|---|
| Type | 64GB LPDDR5 | 4GB LPDDR4 |
| Speed | High bandwidth (256-bit) | Lower bandwidth (64-bit) |
| Aspect | Jetson AGX Orin | Jetson Nano |
|---|---|---|
| Default Storage | 2TB NVMe SSD | microSD card |
| Interface | PCIe Gen 4 | microSD interface |
| Speed | High-speed NVMe | Slower microSD |
| Aspect | Jetson AGX Orin | Jetson Nano |
|---|---|---|
| Networking | 10GbE PCIe (optional) | 1GbE Ethernet |
| USB | USB 3.1, USB 3.2 Gen 2 | USB 3.0 |
| Camera Interfaces | 16x MIPI CSI | 2x MIPI CSI |
| GPIO | Rich GPIO, AI-optimized | Standard GPIO |
It's also important to note that the Jetson Nano is limited to Ubuntu 18.04. With some tweaking, it can be flashed to Ubuntu 20.04, but the underlying driver software that supports the GPU is limited to 10.x or Jetpack 4.x. As such, without even considering hardware limitations, our software can only rely on outdated unoptimized GPU libraries.
The Jetson AGX Orin on the other hand defaults on Ubuntu 20.04 and uses the Jetpack 5.x as the base minimum. This means that out of the box, Jetson AGX Orin already has all the optimized software libraries for GPU-acceleration.
Deliverables
The bare minimum for this paper is to replicate the behavior, at least to some degree. This meant that we had to implement the two core functionalities, which were memory building and query. Below is an image that represents the two phases.
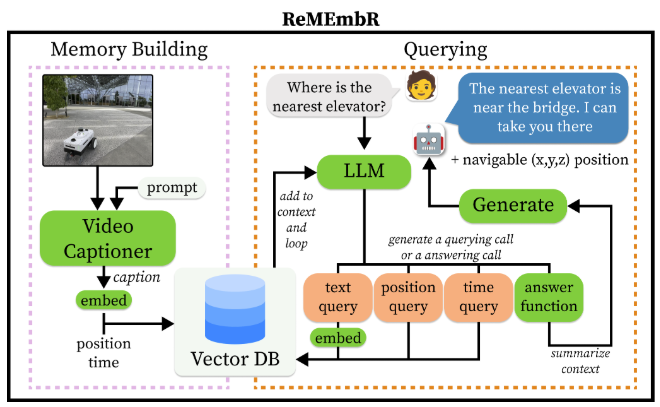
This means we can partition the deliverable into two.
Memory Building
The underlying technology for building memory consists of three core tools.
- 3D/2D SLAM Mapping
- Vision Language model
- Vector Database
- Retrieval Augmented Generation
SLAM
SLAM is simultaneous localization and mapping, which maps the environment around us using LIDAR (light).
Vision Language Model
A Vision Language Model is a deep learning computer vision model that generates additional information alongside the captured scenery. This means that instead of the conventional object detection or segmentation models, each image or a batch of images can have captions which provides natural language information.
Vector Database
A vector database is simply a database that uses the inherent properties of vectors to store data. A vector is an element that belongs to . This is no different than an image that is and we partition the image into different column vectors of . This is useful because we can now apply mathematics for similarity. Before we do so though, we have to encode any non-numerical information into numerics. This can be done by any method.
Retrieval Augmented Generation
Retrieval Augmented Generation allows us to find which vectors are the most similar so that we can deliver the one that's relevant. In this context, given one vector representing a command, we can apply RAG techniques such as cosine-similarity to see which vector within our memory database is the closest. Since we have caption information for our vectors, both query and memory vectors live in the same embedding space.
Implementation Challenges
SLAM
The original paper used 3D LIDAR, but since we had an OAKD-Lite that provided a variety of features such as depth and distance to said object, we only needed 2D LIDAR. Unfortunately, we could not set up SLAM because of environmental incompatibility. Since our Jetson Nano supported Ubuntu 18.04, and the ROS2 framework for DepthAI required Ubuntu versions 20.04 and newer, we had to resort to not using it. This meant that we had to build our own internal boilerplate for figuring out the height.
Vision Language Model
Since we knew the limitations of our hardware, we had to choose another VLM other than the one used in the research paper which was VILA. We first decided to create an MVP to see if it was possible on our personal computer, and saw that it indeed was possible. Below is us utilizing BLIP within the transformers library from HuggingFace. The video below uses only CPU.
We tried to get this to work on our Jetson Nano, but we soon realized it wasn't possible. This was because of the hardware constraints which limited our software environment.
As we previously said, the Jetson Nano supports only Jetpack 4.x and can only support CUDA 10.x. It is also limited to Ubuntu 18.04, which means the Pytorch, Transformer, and Python versions were all limited. Unfortunately, the maximum Transformer version we could use was 4.1x while Pytorch supported 1.10. We were also limited to Python 3.6. There were various things we had to do in order to even install these dependencies. We had to manually install each from a built wheel, and had to build the transformer library from source.
Since we couldn't use BLIP, we decided to partition the vision language model into two parts. A model that utilizes the OAKD-lite on-device VPU to capture embeddings from the image, and a captioner on our Jetson Nano. Unfortunately, we soon realized that in order to do this, we had to train our own model as caption generators does not understand numerical embeddings and as such needed to understand them.
We couldn't get this to work, and as such could not advance onwards to the Vector Database and RAG stage.
Querying
The query phase consists of two core concepts:
- LLM Prompting
- Path Planning
LLM Prompting
The paper compared multiple LLMs, but we decided to use Ollama as it was free. We didn't realize that even if it was free, open source, and locally stored, locally stored meant it ran on our computer. Since we tested it on our computers and worked fine (NVIDIA 20/30 series), we thought it would work on our Jetson Nano. We only realized it after we installed the model onto an 1TB external SSD that it was eating 100% of our CPU and not loading at all. That was because we were using llama3.2, which has 1B and 3B parameters. We switched to gpt2 thinking it wouldn't be that far off, but it was significantly worse than any modern LLMs.
Llama3.2

GPT2
Path Planning
There was no work done for this as we could not get ROS2 SLAM to work. This is as any other path planning there is. Since we have a mapped environment, we can then do path planning.
Environment
We used:
- Ubuntu 18.04
- CUDA 10.2
- Python 3.6
- Pytorch 4.10
- Transformers 4.1x
- ROS2 Dashing,
Pivot
We decided to pivot to another idea, using Human Pose Estimation to using pose to apply various applications such as medical injuries (fall, dislocated, etc), and teaching assistant (posture in class, slouched, etc). This was a great pivot since DepthAI provided the necessary boilerplate and we just needed to create the infrastructure for logic handling.

Future Considerations
In the grand scheme of things, this project was too ambitious for our given time constraint as well as our hardware. If we had a chance to redo this, we would ask for a better Jetson which would have solved all software issues. It is also my personal opinion that I pitched an idea too challenging for my teammates, which meant they did not contribute much.